🩺 Dr.VLA
Sparse Autoencoders Reveal Interpretable and Steerable Features in VLA Models

Abstract
We train Sparse Autoencoders (SAEs) on VLA model activations to discover interpretable features corresponding to motion primitives, semantics, and episode-specific memorization. We show these features causally influence robot behavior through steering experiments, and that fine-tuning on small datasets amplifies memorization while larger datasets or techniques like knowledge insulation promote general features.
Read full abstract
Vision-Language-Action (VLA) models have emerged as a promising approach for general-purpose robot manipulation. However, their generalization is inconsistent, while these models can perform impressively in some settings, fine-tuned variants often fail on novel objects, scenes, and instructions. We apply mechanistic interpretability techniques to better understand the inner workings of VLA models. To probe internal representations, we train Sparse Autoencoders (SAEs) on hidden layer activations from both the language backbone and the action expert. SAEs learn a sparse dictionary whose features act as a compact, interpretable basis for the model's computation. We find that SAEs extract interpretable, general, and steerable features corresponding to motion primitives, semantics, and episode-specific memorization. We categorize features according to whether they represent generalizable transferable primitives or episode-specific memorization. We validate these findings through steering experiments on the LIBERO benchmark. We show that individual SAE features causally influence robot behavior. Steering "generalization" features induce behaviors consistent with their semantic meaning and applicable across tasks and scenes. Our results provide the first mechanistic evidence that VLAs learn generalizable features across tasks and scenes. These results provide mechanistic evidence that VLAs contain both transferable representations and brittle, dataset-specific memorization. We further show that supervised fine-tuning on small robotics datasets disproportionately amplifies memorization, whereas training on larger, more diverse datasets, such as DROID, or leveraging techniques like knowledge insulation appear to promote more general features. Finally, we release an open-source codebase for activation collection, SAE training, and feature steering in VLA models.
Frequently Asked Questions
What does an SAE feature represent, and is it guaranteed to be a single concept?
An SAE feature is a learned latent direction that activates sparsely to help reconstruct a model's internal activations. Concretely, the SAE learns a dictionary where each feature corresponds to one basis direction in activation space, and a given activation vector is represented by a sparse linear combination of these features. In LLMs, many features are strikingly interpretable and can align with localized concepts, but this is not guaranteed. Because there is no theoretical guarantee that a learned direction corresponds to a single human concept, we treat interpretability as an empirical property. We evaluate it by (i) inspecting the highest-activating episodes/timesteps and checking whether the activating contexts share a coherent explanation, and (ii) performing interventions: steering along a feature direction and testing whether it produces predictable, causal changes in model outputs. We assess robustness by training multiple SAEs with different random seeds and verifying that common features reappear.
Why use SAEs instead of PCA, linear probes, or direct MLP activations?
PCA is a global linear decomposition optimized for variance, not interpretability or sparsity. In our preliminary research, we found that PCA decompositions of the activations were not interpretable with respect to episode, task, sub-task, or episode completion. The same applies to inspecting MLP weights directly, as these often exhibit a high degree of superposition among concepts. While linear probes are an excellent choice when supervision data is available, the unsupervised nature of SAEs makes them superior for our exploratory purposes. Our approach is ultimately pragmatic; we aim to use SAEs to identify properties of VLAs that warrant further study.
Are SAEs only for LLMs? How can they work with VLAs, which process many different input types?
SAEs were popularized as a tool for mechanistic interpretability of transformers, but the approach is not language-specific: it is a generic dictionary-learning method over activation vectors. Recent work has extended SAE analysis to multimodal settings, and emerging VLA interpretability work already uses SAE-like interventions to steer action-level behavior. Traditionally, SAEs are trained on a per-token level. However, we find that, for robotics data, the natural base unit is the timestep, which spans many tokens in a VLA model.
What makes this analysis useful if we are not directly improving policy performance?
Mechanistic interpretability can be important even when it does not immediately increase policy performance. With VLAs, especially in their applications to home robotics, safety must go far beyond collision avoidance and stability to a more contextual safety. Understanding how VLAs function is paramount to building the trust required to place them into people's homes. Our feature quantification pipeline allows us to evaluate the generality of a model's features without ever running a single rollout. In this way, we hope interpretability can guide future improvements, even when the immediate goal is understanding rather than performance.
Method Overview
We train Sparse Autoencoders (SAEs) on hidden-layer activations from Pi0.5, a state-of-the-art Vision-Language-Action model. SAEs decompose the model's internal representations into sparse, interpretable features. We analyze features from both the PaliGemma language backbone and the action expert across multiple layers, using the LIBERO and DROID benchmarks.
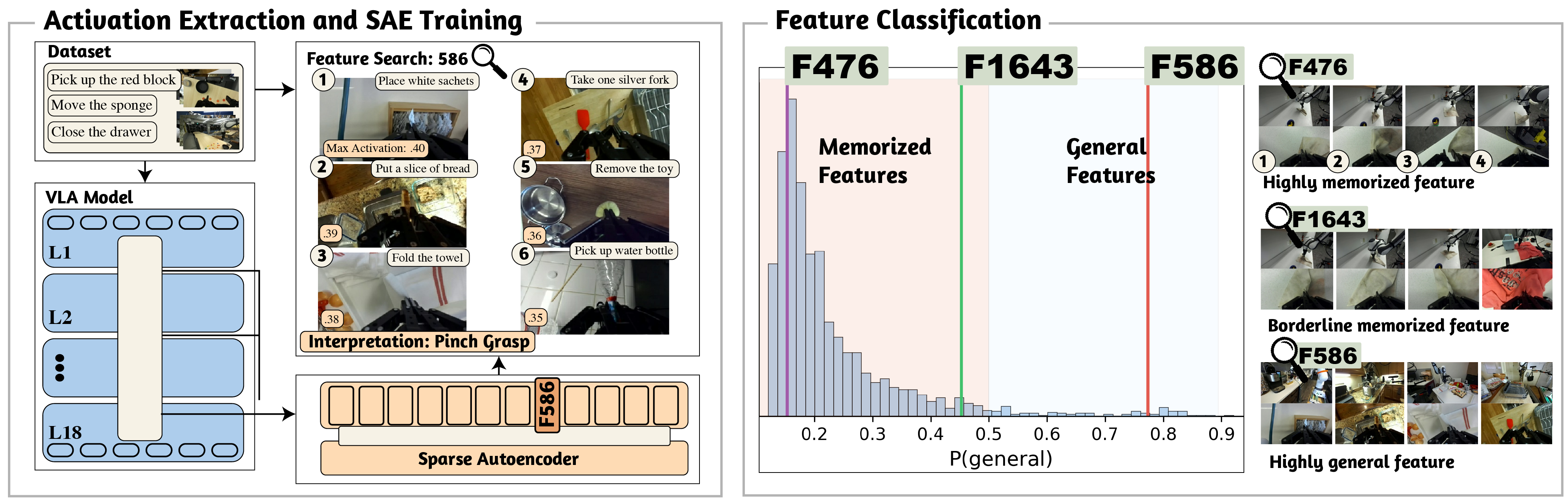
Figure 1: SAE training and analysis pipeline. We collect activations from Pi0.5's internal layers during rollouts, train sparse autoencoders, and analyze the learned features.
General Features
We identify features that activate broadly across episodes, tasks, and scenes -- indicating they encode general motion primitives rather than memorized trajectories. On the LIBERO benchmark, we find 32 general features (out of 2,044 active) in PaliGemma Layer 5.
Interactive Feature Viewer
Each feature shows the top 10 most activated episodes with the peak timestep from each episode. Click on an episode to view sampled frames and activation heatmap.
Loading...
Feature Steering
We validate that SAE features causally influence robot behavior through activation steering. By adding a scaled feature vector to the model's hidden state, we can shift the robot's behavior in predictable ways.
Loading...
Feature Classification
Distribution of four temporal metrics across all SAE features for each model. Dashed line: mean; dotted line: median. Hover over bars for counts.
We develop a logistic-regression classifier to separate general features from memorized ones based on four temporal metrics: onset count, episode coverage, mean activation magnitude, and relative run length.
| Model | Layer(s) | # Features | # General | # Memorized | % Memorized |
|---|---|---|---|---|---|
| Pi0.5 -- LIBERO | |||||
| PG5 | 2,044 | 32 | 2,012 | 98.43% | |
| PG avg (0, 5, 11, 17) | 7,175 | 188 | 6,987 | 97.37% | |
| Pi0.5 -- DROID | |||||
| PG5 | 2,046 | 104 | 1,942 | 94.92% | |
| PG avg (0, 5, 11, 17) | 6,649 | 719 | 5,930 | 89.19% | |
| OpenVLA -- LIBERO Goal | |||||
| Layer 8 | 1,775 | 8 | 1,767 | 99.55% | |
| LM avg (0, 8, 16, 24, 31) | 9,389 | 42 | 9,347 | 99.55% | |
Training on small datasets (LIBERO, 40 tasks) produces far fewer general features than training on large, diverse datasets (DROID, 1,545 tasks).
Per-Token SAEs
We group SAE feature activations by feature across multiple token streams, revealing how each feature distributes its activation across image and text tokens over time. Rows within each feature group are ordered with image tokens first, followed by text tokens sorted by peak activation.
Loading...
Interactive Feature Browser
Browse all 2,048 features from PaliGemma Layer 5
Loading feature data...